Wielu osobom rozpoczynającym przygodę z pozycjonowaniem wydaje się, że większa liczba stron w indeksie oznacza większe korzyści. To mylny pogląd, co dość łatwo możemy udowodnić. Nie chcemy przecież udostępniać stron służących do administracji, tych w przebudowie oraz dostępnych wyłącznie po zalogowaniu. Poniższy artykuł rozjaśnia kwestię tego, jak i po co blokować strony w wyszukiwarce Google.
Czym jest tag noindex? Definicja
Reguła noindex to element umieszczany na stronie internetowej, którego celem jest blokowanie indeksowania. Dzięki niemu boty indeksujące (np. wyszukiwarki Google) nie umieszczą wskazanego adresu URL w swoim indeksie – dana strona nie wyświetli się więc w naturalnych wynikach wyszukiwania. W podobny sposób działa plik robots.txt, w którym umieszcza się adresy URL blokujące dostęp robotom wyszukiwarek.
Jak definiuje Google noindex tag?
Zgodnie z treścią zawartą w Centrum wyszukiwarki Google, noindex jest regułą, którą ustawia się przez użycie tagu <meta>, służącego do zapobiegania indeksowaniu treści przez roboty Google. Jeśli roboty indeksujące napotkają adresy URL stron zawierających wspomnianą regułę, wyeliminują je z wyników wyszukiwania Google niezależnie od tego, czy na innych stronach internetowych znajdują się prowadzące do nich odnośniki.

Google radzi, aby blokować indeksację nie tylko w pliku robots.txt, ale także poprzez wdrożenie noindex, który całkowicie wyeliminuje strony oznaczone tagiem z wyników wyszukiwania.
Jak zastosować tag noindex na stronie?
Blokowanie indeksowania przy pomocy noindex jest bardzo proste. Otwórz kod źródłowy adresu URL w systemie CMS i dodaj do nagłówka (sekcja <head>) jedną z przedstawionych wartości:
-
<meta name=”robots” content=”noindex”> – dla blokowania indeksowania wszystkich wyszukiwarek
-
<meta name=”googlebot” content=”noindex”> – dla blokowania indeksowania w Google
W niektórych systemach CMS implementacja tagu noindex oraz blokowanie indeksowania odbywa się przy pomocy specjalnej wtyczki. Wówczas nie musisz ręcznie umieszczać wartości w kodzie źródłowym strony.
Kiedy stosować blokowanie indeksowania?
Pierwszym przypadkiem, kiedy będzie trzeba wykorzystać blokowanie indeksowania w Google, są początki jej tworzenia. Nie musisz być specjalistą SEO, aby zrozumieć, że publikowanie podstron bez zawartości czy z zawartością testową (np. lorem ipsum) do niczego dobrego się nie przyczyni.
Wyszukiwarka Google od czasów wdrożenia algorytmu Panda ceni sobie unikalną zawartość i to, co jest rzeczywiście przydatne dla użytkownika. Dlatego zachowaj cierpliwość i pozostaw indeksowanie strony wyłączone, dopóki na stronie nie będzie widnieć oficjalna zawartość, którą sam chciałbyś zobaczyć jako użytkownik sieci.
Istnieje szansa, że po opublikowaniu danej witryny niektóre z podstron zwyczajnie nie będą potrzebne w indeksie wyszukiwarki. Najczęściej chodzi o stronę logowania do panelu administracyjnego, strony produktów, których nie ma w magazynie oraz zamkniętej części serwisu np. prywatne grupy dyskusyjne na portalach.
Sens blokowania indeksacji leży w sposobie działania robotów Google. Mianowicie biorą one pod uwagę daną liczbę adresów w określonym czasie. Każda domena ma osobisty budżet indeksowania. Jeśli zostanie przekroczony, to kolejne podstrony zostaną zaindeksowane dopiero po czasie.
W kontekście SEO jednym z największych zagrożeń jest duplikowana treść. O ile jej powtarzalność w obrębie naszego serwisu nie stanowi ogromnego problemu, o tyle zapożyczona zawartość z innych stron będzie skutkowała pogorszeniem reputacji i obniżeniem rankingu.
Jeśli skopiowaliśmy cały artykuł, a chcemy go koniecznie zachować, to jednym z rozwiązań jest ponownie – wyłączenie danej podstrony z indeksu za pomocą tagu noindex. Pamiętajmy! Jeśli posiadamy dwie identyczne lub bardzo zbliżone wersje podstron, to wszystkie kopie powinniśmy oznaczyć jako duplikaty za pośrednictwem tagu link w takiej postaci:
<link rel=”canonical” href=”https://adres-oryginalnej-strony.com/adres-oryginalnej-podstrony ” />.
Takie rozwiązanie jest stosowane między innymi podczas pozycjonowania stron, gdy realizuje się czynności optymalizacyjne.
Podstrony, które warto zablokować w sklepie internetowym
Sklepy internetowe rządzą się swoimi prawami. W odróżnieniu od zwykłego bloga, portfolio czy landing page’a, charakteryzują się znacznie bogatszą funkcjonalnością. To generuje niepotrzebne w wynikach wyszukiwania Google podstrony. Warto sprawdzić, czy roboty wyszukiwarek indeksują konkretne podstrony:
-
formularze zachęcające do subskrypcji newslettera, wysłania komentarza czy rejestracji,
-
filtry kategorii, strony sortowania,
-
politykę prywatności, plików cookies, regulaminy,
-
paginację, którą można przekierowywać na pierwszą stronę kategorii,
-
strony wewnętrznych wyników wyszukiwania,
-
tagi, jeśli liczba produktów pod tagiem jest mała,
-
puste podstrony produktowe lub te, których nie będzie w magazynie dłuższy czas.
Jak widać, lista elementów jest dość długa. A to oznacza, że wykluczenie tych elementów z wyników wyszukiwania stwarza dużą przestrzeń na usprawnienie wędrówki googlebota.

Jak wykluczyć strony z indeksacji poza zastosowaniem tagu noindex?
Korzystanie z blokady indeksowania wymaga od nas zastosowania jednego z dwóch narzędzi: pliku .htaccess lub wbudowanego w system zarządzania treścią (CMS) pluginu.
Gdy rozpoczynamy tworzenie strony www, możemy postawić na globalne blokowanie indeksowania. Dopiero po zakończeniu prac będziemy mogli wrócić do pożądanego ustawienia. Taka opcja jest dostępna w większości CMS-ów z poziomu panelu administracyjnego. Jeśli jej tam nie ma, to częstokroć zapewni ją dodatkowe rozszerzenie lub plugin.
Jak ukryć strony w wyszukiwarce Google?
Zablokujesz stronę wykorzystując aż cztery różne metody.
Pierwszym sposobem jest wstawienie odpowiedniego kodu do sekcji head strony internetowej. To wcześniej wspomniany tag noindex.
Podobnie zadziała dyrektywa wstawiona do pliku robots.txt, którego miejsce jest w głównym katalogu na naszym serwerze (tam, gdzie plik index.php).
Uwaga! Aby tag noindex zadziałał poprawnie, nie możesz blokować strony lub jej zasobów w pliku robot.txt ani w inny sposób uniemożliwiać robotowi dostępu.
Do pliku możemy wstawić kilka linijek:
-
User-Agent: *
-
Disallow: /wybrany-katalog/podstrona.php
Trzecim sposobem jest wykorzystanie instrukcji w języku PHP. Oczywiście musimy z tej technologii korzystać, z czego coraz więcej twórców CMS rezygnuje. Niemniej, jeśli jeszcze korzystamy z PHP, to możemy zablokować dostęp robotom do strony, dodając następujący kod:
-
header („X-Robots-Tag: noindex”, true);
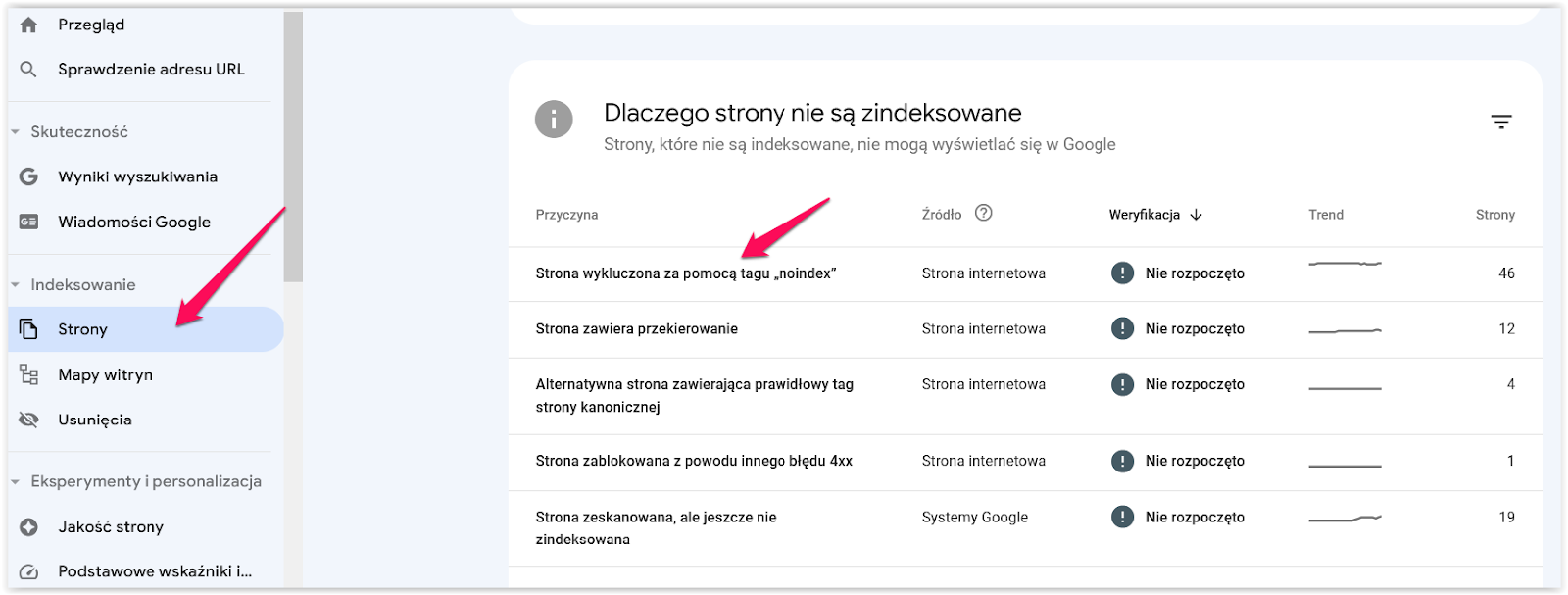
Ostatnią metodą jest tymczasowe wykluczenie z indeksu. Swoją prośbę możemy przesłać za pośrednictwem Google Search Console. Wystarczy wejść do zakładki Indeks -> Usunięcia i zlecić swoją prośbę podając wybrany URL.
FAQ dotyczące blokowania indeksowania oraz tagu noindex
#1 Definicja noindex
Tag noindex to znacznik umieszczany w sekcji <head> strony internetowej, który wskazuje robotom wyszukiwarek, aby nie indeksowały danej strony. Reguły noindex są wartością, którą można przypisać dyrektywie Robots Meta. W rezultacie wyszukiwarka całkowicie wyeliminuje stronę z darmowych wyników wyszukiwania.
#2 Jak zablokować indeksowanie na stronie internetowej?
Blokowanie indeksowania może być wdrożone poprzez implementację tagu noindex lub dodanie odpowiednich wartości do pliku robots.txt.
#3 Jak powinien wyglądać tag noindex?
Prawidłowo zaprojektowany tag noindex wygląda następująco: <meta name=”robots” content=”noindex”>.
#4 Czy tag noindex może być dodany przy pomocy wtyczki?
Wiele systemów CMS pozwala blokować indeksowanie tagiem noindex przy pomocy wtyczki. W przypadku WordPressa, taki plugin to: „noindex SEO”.
#5 Jak pozwolić robotom na indeksację strony?
Zrobisz to usuwając tag noindex lub nagłówek HTTP noindex i wklejając adres URL w Google Search Console.
#6 Czy tag noindex blokuje roboty przed odwiedzaniem strony?
Nie. Tag noindex zapobiega jedynie wyświetlaniu strony w organicznych wynikach wyszukiwania, ale roboty wciąż mogą na nią wejść i przeanalizować jej treść. Aby całkowicie zablokować dostęp, należy użyć pliku robots.txt lub ograniczeń dostępu na serwerze.
#7 Czym się różni tag noindex od nofollow?
Tag noindex i nofollow mają różne zastosowania w optymalizacji SEO:
-
meta tag noindex wskazuje robotom wyszukiwarek, aby nie indeksowały strony, co oznacza, że nie pojawi się ona w wynikach wyszukiwania.
-
tagiem nofollow informujemy roboty, aby nie podążały za linkami znajdującymi się na stronie, co powoduje, że nie przekazują one wartości SEO (tzw. „link juice”) stronom, do których prowadzą.

swój potencjał z

polityką prywatności

























![Najpopularniejsze platformy e-commerce w Polsce – ranking [TOP 11]](https://semcore.pl/wp-content/uploads/2024/07/q-36-150x150.jpg)


