
Firmy mają do dyspozycji coraz więcej danych, na podstawie których mogą podejmować decyzje. Samo ich posiadanie to jeszcze nie wszystko – trzeba je jeszcze odpowiednio organizować, przetwarzać, zabezpieczać i udostępniać. Tutaj pojawia się metodologia DataOps, która służy optymalizowaniu zarządzania danymi w cyklu ich życia. O co właściwie chodzi i jak to działa?
Czym jest DataOps?
DataOps nie jest pojedynczym narzędziem, tylko podejściem, które zakłada automatyzację i ciągłe doskonalenie procesów związanych z obsługą danych. Chodzi o ich szybsze dostarczanie, dbałość o jakość, użyteczność i zgodność. Efektem zastosowania tej metodologii jest bardziej przewidywalne i szybsze działanie organizacji.
DataOps to także zbiór praktyk wzorowany na modelu DevOps, który skupia się na koordynacji procesów zarządczych i analizie danych. Obejmuje automatyczne przesyłanie danych między systemami, identyfikowanie i usuwanie błędów oraz niespójności, a także ograniczenie powtarzalnych czynności wykonywanych ręcznie.
Źródło: https://www.xenonstack.com/insights/data-operations
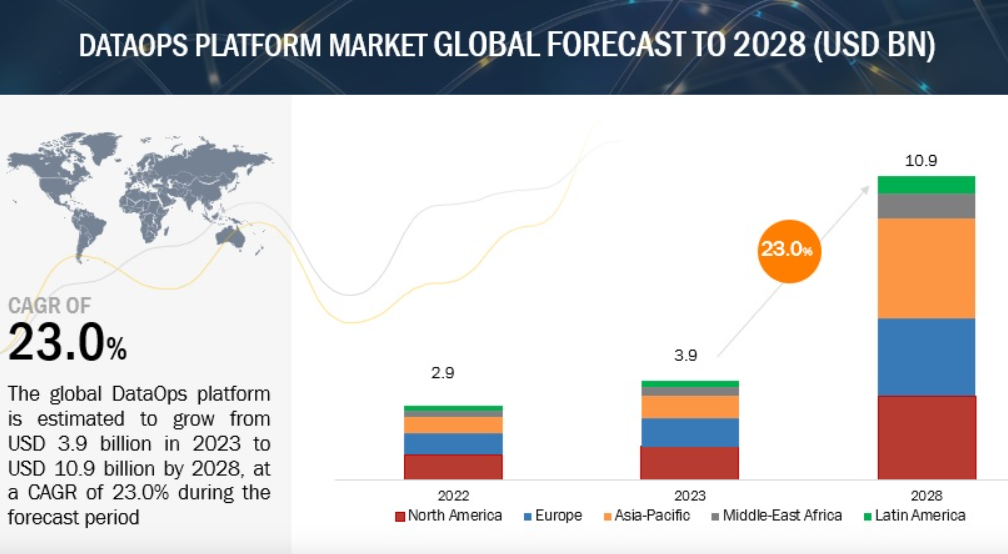
Uwaga: szacuje się, że wartość rynku platform DataOps wzrośnie z 3,9 mld USD w 2023 r. do 10,9 mld USD w 2028 r.
Źródło: https://www.marketsandmarkets.com/Market-Reports/dataops-platform-market-28879938.html
Ogromny wzrost liczby danych powoduje, że firmy nie nadążają z analizą za pomocą tradycyjnych procesów. DataOps pomaga wyeliminować te i inne ograniczenia. Dzięki automatyzacji powtarzalnych przepływów pracy i poprawie jakości danych przyspiesza czas uzyskania wglądu w dane.
DataOps a DevOps – podobieństwa i różnice
Obie te koncepcje opierają się na tych samych, podstawowych zasadach, czyli wydajności, automatyzacji i ciągłym doskonaleniu. Jednak stosuje się w nich te zasady w inny sposób. DevOps koncentruje się na tworzeniu oprogramowania i robieniu tego lepiej poprzez usprawnienie cyklu tworzenia, testowania i wdrażania aplikacji oraz usług.
DataOps skupia się natomiast na przepływie danych. Zamiast optymalizować wdrażanie kodu, koordynuje przepływ danych w całym cyklu ich życia – od pozyskiwania i transformacji po walidację i dostarczanie.
Upraszczając, DevOps przyspiesza dostarczanie oprogramowania, a DataOps dostarczanie danych. Obie koncepcje opierają się na automatyzacji i zasadach ciągłej integracji, ale rozwiązują różne problemy dla różnych interesariuszy.
Cykl życia DataOps
DataOps opiera się na cyklu życia, który określa, w jaki sposób informacje z surowych danych wejściowych stają się gotowymi do wykorzystania. Cykl ten składa się z pięciu głównych etapów:
- Pobieranie – czyli przenoszenie surowych danych ze źródeł wewnętrznych i zewnętrznych do hurtowni danych. Dane te są integrowane w jeden format, który stanowi punkt wyjścia do analiz i uczenia maszynowego.
- Koordynacja – zbiory danych są porządkowane i przygotowywane do analizy.
- Walidacja – w ramach zautomatyzowanych testów dane są sprawdzane pod kątem kompletności, spójności i dokładności.
- Wdrażanie – dane są przekazywane analitykom i do modelu uczenia maszynowego. Wykorzystuje się je przy podejmowaniu decyzji i w dalszych procesach analitycznych.
- Monitorowanie – narzędzia do obserwacji śledzą wydajność i użyteczność danych.
Czy Twoja firma na pewno potrzebuje DataOps?
Zdecydowanie tak, jeśli przetwarzasz dużą liczbę danych. Dzięki zastosowaniu DataOps możesz wielokrotnie skrócić czas dostarczania analiz w firmie. Zastosowanie wersjonowania danych i automatyzacji procesów dają możliwość wprowadzania poprawek w czasie rzeczywistym. DataOps poprawia jakość danych i umożliwia śledzenie wszystkich modyfikacji. Poza tym w ten sposób zmniejsza się również liczbę błędów, a także można skalować operacje analityczne.
Jaka jest przyszłość DataOps?
DataOps, dzięki rozwojowi automatyzacji, może się stać jednym z kluczowych elementów w biznesie. Uczenie maszynowe w coraz większym stopniu automatyzuje zadania, takie jak wzbogacanie metadanych i dostosowywanie schematów.
DataOps w coraz większym stopniu będzie synchronizować przepływy danych między brzegiem (czyli urządzeniami znajdującymi się blisko miejsca powstawania danych) a chmurą, wspierając przetwarzanie o niskim opóźnieniu bez poświęcania scentralizowanego zarządzania, śledzenia pochodzenia danych czy kontroli jakości. Zarządzane platformy DataOps oparte na chmurze będą obniżać bariery wdrożeniowe, zapewniając wbudowane funkcje koordynacji, monitorowania i zarządzania. Dzięki tym możliwościom narzędzia DataOps są łatwiejsze do wdrożenia i utrzymania.

swój potencjał z

polityką prywatności



























![Najpopularniejsze platformy e-commerce w Polsce – ranking [TOP 11]](https://semcore.pl/wp-content/uploads/2024/07/q-36-150x150.jpg)


