
LLMy w ciągu niecałych trzech lat od premiery pierwszej publicznej wersji ChatGPT zdążyły nie tylko zmienić internet, ale też przemodelować workflow milionów firm. W tym artykule omówimy, co oferują dziś najpopularniejsze modele językowe. Zapraszamy do lektury!
Modele GPT (Open AI)
Mówisz „AI”, prawdopodobnie myślisz „ChatGPT”. Dziś jego flagowym modelem jest GPT-5 i śmiało można go traktować jako benchmark dla innych LLMów. „Piątka” to model all-in-one – świetnie radzi sobie we wszystkich ważnych obszarach (rozumienie języka, analiza danych, logika, programowanie), jest multimodalny (poza tekstem przetwarza również obraz i dźwięk) oraz wyposażony w tryb deep reasoning, który wymusza na modelu zdecydowanie dłuższą, bardziej pogłębioną analizę przed udzieleniem odpowiedzi na prompt.
Oczywiście, GPT-5 pozostaje modelem komercyjnym (a więc płatnym), a OpenAI trzyma w tajemnicy informacje o tym, jak dokładnie wygląda baza danych treningowych i na jakich parametrach pracuje sam model. Ostatnio jednak firma Sama Altmana udostępniła dwa modele open-weight – GPT-oss-120b i GPT-oss-20b, w których można samemu modyfikować parametry przetwarzania języka.

fot. Jonathan Kemper / Unsplash.com
Ciekawostką jest, że OpenAI testuje obecnie funkcję tzw. „memory on demand”, która pozwala GPT-5 zapamiętywać informacje pomiędzy sesjami – np. o Twoich preferencjach czy stylu pracy. Funkcja ta wciąż jest eksperymentalna, ale może zrewolucjonizować sposób korzystania z LLM-ów, sprawiając, że staną się bardziej spersonalizowane i „partnerskie” w codziennym użyciu.
Gemini (Google)
Google ma jeszcze dłuższą historię, jeśli chodzi o rozwój AI – bo to inżynierzy z Mountain View wypracowali całą architekturę uczenia głębokiego opartą na transformerach, z której wywodzi się m.in. GPT… oraz właśnie Gemini.
Na tle GPT najnowszy model – Gemini 2.5 – wyróżnia się na trzech polach.
Po pierwsze, szybkość przetwarzania danych. Tempo, z jakim chatbot Google generuje odpowiedzi jest imponujące już na pierwszy rzut oka, a benchmarki tylko to potwierdzają; wg Artifical Analysis gdy GPT-5 generuje 87 tokenów („jednostek” informacji, na przykład tekstu), Gemini 2.5 Pro tworzy ich… 145. Druga przewaga? Multimodalność. Model od Google po prostu lepiej radzi sobie z kompilacją danych z różnych źródeł (tekst, dźwięk, obraz), potrafi też interpretować informacje z plików wideo. Do tego ma też szersze okno kontekstowe – milion tokenów vs. 400 tysięcy w GPT-5 – to znaczy jest w stanie „zapamiętać” i analizować więcej danych na raz.
Tak naprawdę jedynym polem, na którym Gemini wciąż odstaje, jest… sama „inteligencja” modelu; w testach MMLU wersja Pro plasuje się i za GPT-5, i za najmocniejszym wariantem Claude, o którym poniżej.
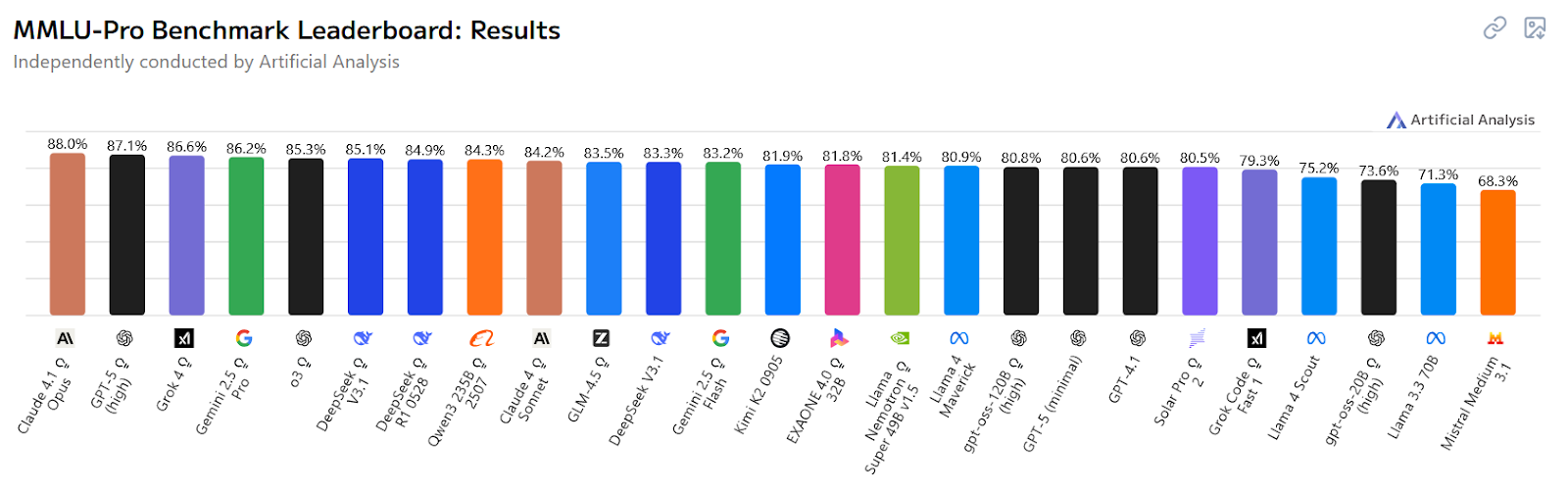
Zdj 1. Czołówka modeli językowych wg wyników testów MMLU z września 2025 roku.
Źródło: https://artificialanalysis.ai/evaluations/mmlu-pro
Gemini 2.5 jest też mocno zintegrowany z ekosystemem Google – wbudowane w Workspace i wyszukiwarkę ma szansę stać się domyślnym asystentem dla milionów użytkowników. Jeśli firma utrzyma tempo rozwoju, możliwe że w 2026 zobaczymy Gemini 3, który – według przecieków – ma kłaść duży nacisk na interpretację danych w czasie rzeczywistym, co może być przełomem np. dla analizy transmisji live czy wirtualnych spotkań.
Claude (Anthropic)

fot. Solen Feyissa / Unsplash.com
Modele od Anthropic wydają się być nieco mniej znane w Polsce, a niesłusznie – Claude stanowi mocną konkurencję dla GPT. Flagową wersją modelu jest obecnie Claude 4, dostępny w dwóch wariantach: Opus i Sonnet; ten pierwszy stworzony jest raczej z myślą o złożonych zadaniach biznesowych czy o kodowaniu, drugi – o codziennej pracy (dobrze sprawdzi się np. przy redakcji tekstów pod pozycjonowanie).
A dlaczego warto się nimi zainteresować? Claude 4 osiąga naprawdę świetne wyniki w zadaniach wieloetapowych, zwłaszcza z extended thinking mode – czyli rozszerzonym trybem rozumowania, w którym model wchodzi w tzw. pętle autorefleksji; analizuje krok po kroku każdą możliwą ścieżkę rozumowania, wybiera najlepszą i dopiero potem udziela odpowiedzi. Pomaga to ograniczyć halucynacje przy analizie większych zbiorów danych, chociaż – oczywiście – sprawia też, że model jest trzykrotnie mniej wydajny od np. Gemini 2.5 Pro.
Warto dodać, że Anthropic mocno inwestuje w rozwój AI bezpiecznej i zgodnej z zasadami etyki – Claude ma wbudowane tzw. Constitutional AI, czyli zestaw reguł etycznych, które pomagają modelowi unikać kontrowersyjnych odpowiedzi. To podejście jest szczególnie doceniane przez firmy z sektora finansowego i medycznego, które muszą spełniać rygorystyczne wymagania regulacyjne.
Llama (Meta)
Na koniec model od twórców Facebooka. Meta weszła w świat dużych modeli językowych z zupełnie innym podejściem niż konkurenci; zamiast tworzyć kolejne komercyjne „czarne skrzynki”, o których parametrach wiemy albo nic, albo bardzo niewiele, postawiła na model open source. Tak więc wszystkie modele z serii Llama można pobrać, uruchomić lokalnie (wystarczy przyzwoity MacBook z 16 GB RAMu) i dowolnie modyfikować pod własne potrzeby. Wokół Llamy rozwinął się już cały ekosystem – od narzędzi ułatwiających instalację (jak Ollama), przez platformy do fine-tuningu, po tysiące customowych wersji dostępnych na Hugging Face.
W tym wszystkim kryje się jeden minus: fakt, że w testach wymagających głębszego rozumowania nawet najmocniejszy model, Llama 4 Maverick, ma sporo do nadrobienia względem GPT-5 czy choćby Gemini 2.5 Flash, który ma być przecież „lekkim” LLMem.
Przewagą Llamy jest jednak to, że pozwala firmom budować w pełni prywatne rozwiązania – bez konieczności wysyłania danych do chmury. Dzięki temu Llama staje się popularnym wyborem w branżach, w których poufność danych jest kluczowa (np. prawo, medycyna czy sektor publiczny). Meta zapowiada, że w przyszłości planuje jeszcze lżejsze wersje modeli, które będzie można uruchomić nawet na smartfonach.
Jak widać, świat LLM-ów rozwija się w błyskawicznym tempie – od potężnych, komercyjnych rozwiązań w stylu GPT-5 czy Gemini, przez etycznie projektowanego Claude’a, aż po w pełni otwarte modele, jak Llama. Każdy z nich ma swoje mocne i słabsze strony, dlatego warto testować różne narzędzia i sprawdzić, które najlepiej pasują do Twoich potrzeb – niezależnie od tego, czy zależy Ci na szybkości, prywatności, czy kreatywnych możliwościach AI.

swój potencjał z

polityką prywatności





























![Najpopularniejsze platformy e-commerce w Polsce – ranking [TOP 11]](https://semcore.pl/wp-content/uploads/2024/07/q-36-150x150.jpg)


