
Google wprowadził swoją nową wizję przyszłości wyszukiwania online, opartą na technologii sztucznej inteligencji (AI). Innowacja ta wywołała falę krytyki w branży, obawiającej się, że może ona zniszczyć otwarty ekosystem internetu. W centrum kontrowersji znajdują się nowe „AI Overviews” Google’a – generowane podsumowania, które bezpośrednio odpowiadają na zapytania użytkowników, czerpiąc informacje z różnych stron internetowych.

Źródło: https://img.freepik.com/free-photo/ai-face-concept-ai-generated_268835-9216.jpg?t=st=1716033575~exp=1716037175~hmac=a78581b947a7263f7354c9a88c8dd0e33685d3e9de5eff97cde146a04591b65f&w=1380
Jak działają AI Overviews?
AI Overviews pojawiają się na szczycie wyników wyszukiwania, ograniczając potrzebę klikania w linki prowadzące do witryn wydawców. Wielu wydawców wyraziło swoje obawy, twierdząc, że taka praktyka narusza ich prawa autorskie, gdyż Google używa ich treści do trenowania swoich modeli AI bez uzyskania zgody.
Reakcje wydawców
W kwietniu 2024 roku grupa francuskich wydawców wygrała wstępną batalię sądową, zmuszając Google do negocjacji w sprawie uczciwego wynagrodzenia za wykorzystywanie ich treści. Podobne działania rozważają również wydawcy w USA, argumentując, że Google nieuczciwie czerpie korzyści z cudzej pracy. Raptive, firma zajmująca się usługami reklamowymi, szacuje, że zmiany te mogą spowodować straty w wysokości 2 miliardów dolarów dla twórców treści online, a niektóre witryny mogą stracić aż dwie trzecie swojego ruchu.
Problemy branżowe
Google od lat opiera swój model biznesowy na przekierowywaniu ruchu do innych witryn i monetyzowaniu go poprzez kanały reklamowe. Nowe AI Overviews mogą zmienić ten model, co budzi uzasadnione obawy wśród profesjonalistów z branży.
Matt Gibbs, komentując rozwój AI przez Google, stwierdził wprost: „Oni ukradli to od wydawców, którzy wykonali prawdziwą pracę tworząc tę wiedzę. Google to banda złodziei”.
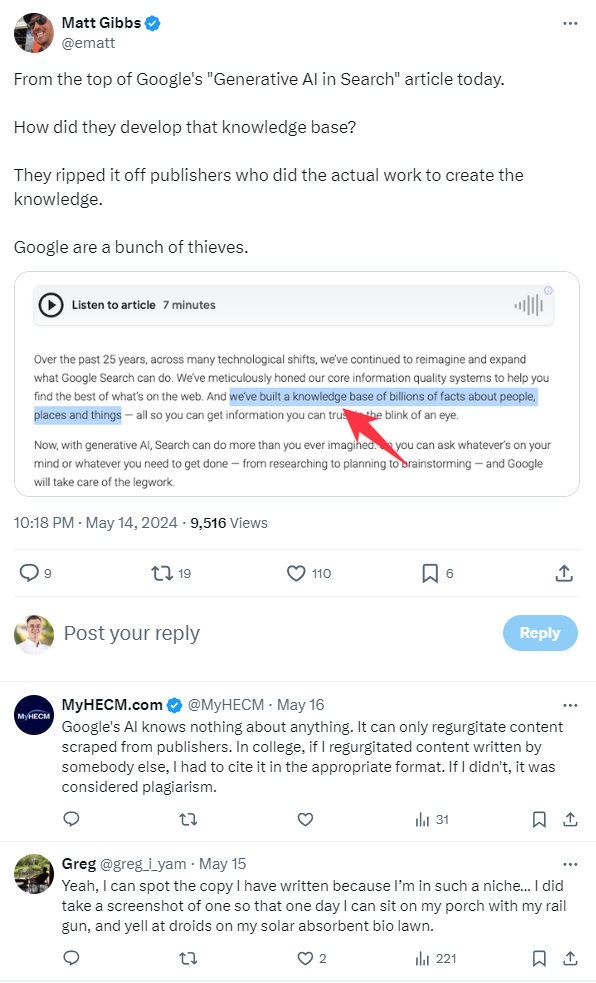
Zdj 1. Wypowiedź autora Matt Gibbs na temat Google.
Źródło: x.com/ematt/status/1790476863430918574
Problemy prawne
Kontrowersje te wpisują się w szersze debaty dotyczące własności intelektualnej i dozwolonego użytku, ponieważ systemy AI są trenowane na ogromnych ilościach danych zgromadzonych w Internecie. Google twierdzi, że jego modele wykorzystują jedynie publicznie dostępne dane, a wydawcy korzystali z ruchu generowanego przez wyszukiwarki. Niemniej jednak przepisy nie były tworzone z myślą o trenowaniu modeli AI.
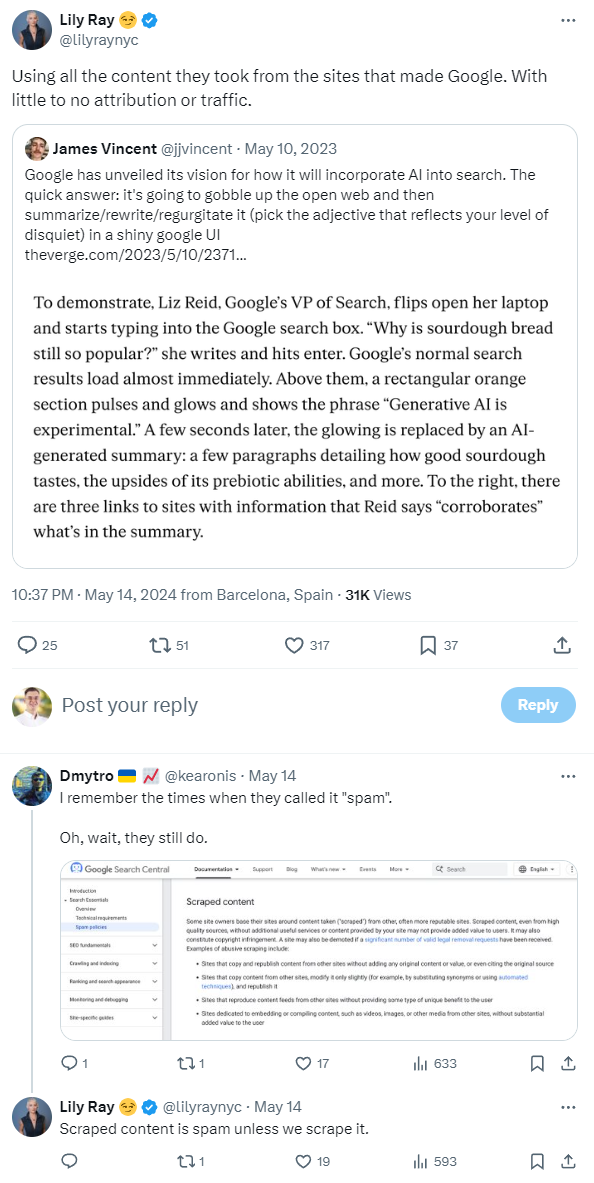
Zdj 2. Wypowiedź Lily Ray.
Źródło: x.com/lilyraynyc/status/1790481616910917992
Ścieżka do przyszłości – jak to wygląda w praktyce?
Omówiona debata podkreśla potrzebę wprowadzenia nowych regulacji dotyczących wykorzystywania danych online przez AI. Istnieje kilka możliwych ścieżek rozwiązania tego problemu:
- dzielenie się przychodami lub opłaty licencyjne za wykorzystanie treści wydawców do trenowania modeli AI;
- system opt-in, który daje właścicielom witryn większą kontrolę nad tym, jak ich treści są wykorzystywane do trenowania AI.
Współzależność między wyszukiwarkami a twórcami treści była dotąd kluczowym elementem działania internetu. Jeżeli równowaga ta zostanie zachwiana bez wprowadzenia nowych zabezpieczeń, może to zagrozić wymianie informacji, która czyni internet tak wartościowym.

swój potencjał z

polityką prywatności






















![Najpopularniejsze platformy e-commerce w Polsce – ranking [TOP 11]](https://semcore.pl/wp-content/uploads/2024/07/q-36-150x150.jpg)


