Supplemental Index – co to jest i jak go znaleźć?
Spis treści
Spis treści
Istnieją w branży SEO (ang. Search Engine Optimization) pojęcia historyczne, które warto znać. Jednym z nich jest Supplemental Index. Pomimo że dzisiaj wyszukiwarka nie utrzymuje tego rozwiązania, wskazuje ono wciąż aktualną wartość parametrów technicznych stron internetowych. Sprawdź najważniejsze informacje na temat tego, czym jest Google Supplemental Index i jak można było go znaleźć.
Co to jest Supplemental Index?
Supplemental Index, czyli poboczny indeks wyszukiwarki jest indeksem, w którym zawarte były strony internetowe lub ich podstrony. Chodzi o adresy, które Google w procesie wyszukiwania uznało za niezaufane. Za mało wartościowe, mało unikalne lub zduplikowane.
Indeks ten został wdrożony w 2003 roku. Supplemental Index to obecnie termin historyczny, Google zaprzestało bowiem jego stosowania w 2007 roku. Połączyło wtedy Supplemental Indeks z głównym indeksem. Zmiana ta wynikała z postępu w technologii indeksowania oraz z rozwoju algorytmów. Dzisiaj dostępne jest bardziej spójne i jednolite podejście do analizy i przetwarzania treści internetowych.
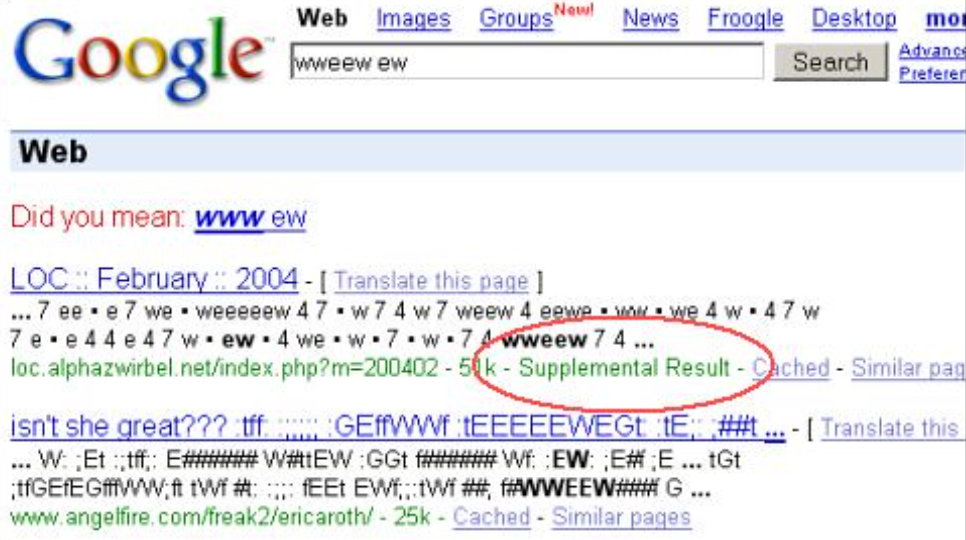
Zdj. 1. Wygląd Supplemental Index w Google
Źródło: https://www.flickr.com/photos/abelgv/125128136/
Jaka była funkcja Google Supplemental Index?
Celem wprowadzenia Google Supplemental Index była poprawa efektywności oraz szybkości wyszukiwania przez użytkowników. Twórcy wyszukiwarki chcieli jednocześnie, aby zachować szeroki dostęp do zasobów. Tym samym Supplemental Index (poboczny indeks wyszukiwarki) pozwalał na lepsze zarządzanie skalą rosnącej ilości danych do przetworzenia. Odnośniki, które znajdowały się w Supplemental Index, nie miały żadnej mocy SEO. W związku z tym wyszukiwarka ignorowała je lub dawała im bardzo niską wartość.
Kiedy podstrony trafiały do Supplemental Index?
Google nigdy nie udostępniło publicznie szczegółowych kryteriów na temat tego, kiedy adresy były przydzielane do Supplemental Index. Można było jednak wyciągnąć pewne wnioski, analizując adresy URL. Kiedy więc podstrony tam trafiały? Były to przypadki, takie jak:
- błąd 404 lub URL z wygasłych domen.
- starsze wersje podstron.
- zduplikowane adresy URL.
- przekierowane adresy URL (301 lub 302).
- zbyt długie lub skomplikowane adresy URL.
- podobne lub identyczne meta tagi i tytuły.
- orphaned pages (podstrony bez linków) – tzw. osierocone strony.
- podstrony bez treści.
- podejrzane treści.
- podstrony z niskim TrustRank (ocena algorytmu odpowiedzialnego za analizę linków).
Często przyczyną trafienia podstron do Supplemental Index był zbyt szybki rozwój witryny.
Jak można było znaleźć podstrony witryny w Supplemental Index
Jednym z najprostszych sposobów na sprawdzenie, czy dana podstrona znajdowała się w Supplemental Index, było wykorzystanie odpowiedniej komendy w wyszukiwarce Google. Chodzi tutaj o wpisanie:
site:nazwadomeny.pl.
Następnie można było przejrzeć całą listę adresów URL i szukać w nich oznaczenia Supplemental Index.
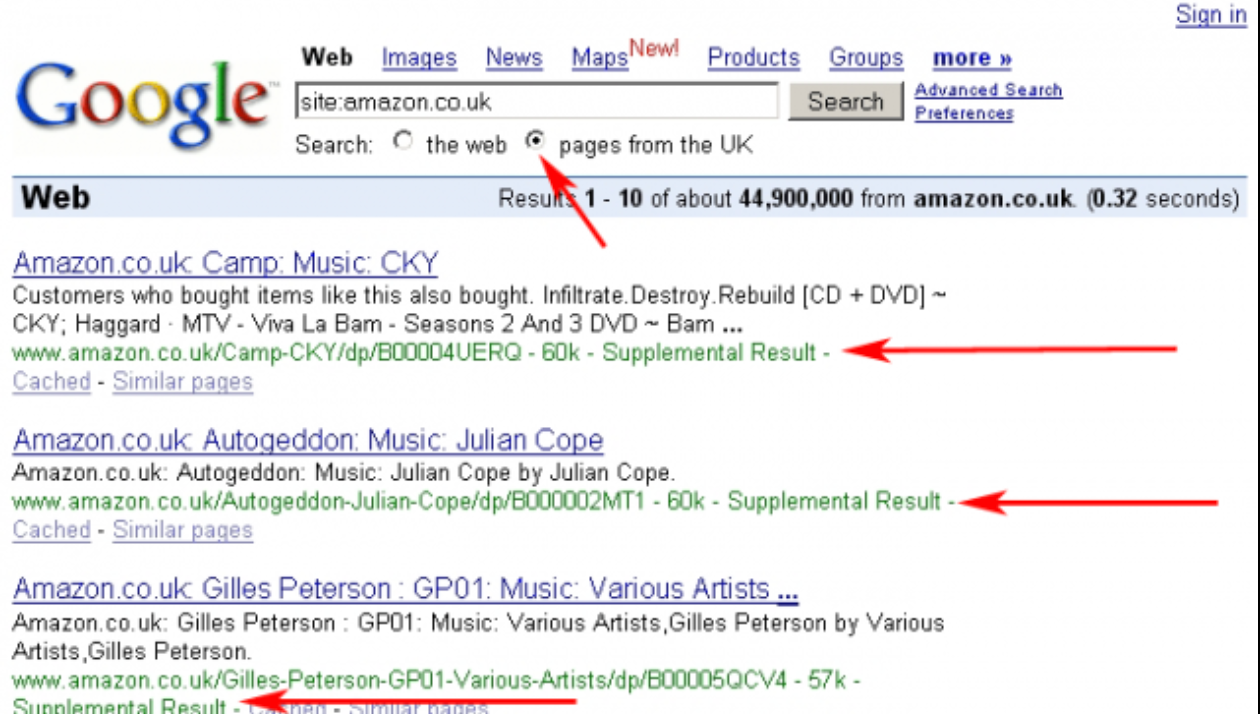
Zdj. 2. Weryfikacja wyników wyszukiwania z Supplemental Index:
Źródło: https://www.seroundtable.com/google-supplemental-index-dead-33656.html
Jak można było przenieść podstrony do głównego indeksu?
Aby przenieść podstrony witryny z Supplemental Index do głównego indeksu Google, konieczne było zoptymalizowanie treści, linkowania oraz aspektów technicznych. Tworzono unikalne oraz wartościowe teksty, eliminowano duplikaty i dbano o jakość linków wewnętrznych oraz zewnętrznych. Poprawiała się tym samym dostępność treści dla robotów Google.
Supplemental Index — podsumowanie
Supplemental Index to historyczne rozwiązanie Google. Rozwiązanie wprowadzone w 2003 roku w celu optymalizacji procesu wyszukiwania i zarządzania dużymi ilościami danych w internecie. Istotne w kontekście pożądanego nieindeksowania adresów w Supplemental Index były dobre parametry techniczne witryn.
Do dzisiaj skuteczne pozycjonowanie wymaga pracy nad tym aspektem. Oczekiwania algorytmów wobec stron internetowych ciągle ewoluują, a eksperci SEO muszą być na bieżąco z rosnącymi wymaganiami.

swój potencjał z

polityką prywatności


